本站资源限时全部免费
开启辅助访问
切换到窄版
登录
立即注册
首页
论坛
前线论坛
频道
软件
插件
Plugin
网课
搜索
搜索
每日签到
本版
文章
帖子
用户
QQ前线乐园
»
论坛
›
前线大厅
›
QQ教程篇
›
数字化时代下:利用爬虫技术抓取微博话题热度数据做舆情 ...
返回列表
发新帖
数字化时代下:利用爬虫技术抓取微博话题热度数据做舆情监控分析
[复制链接]
668
|
0
|
2025-2-2 11:12:09
|
显示全部楼层
|
阅读模式
当前,数字化潮流席卷而来,社交媒体已成为信息流通的主要通道。微博作为重要的短文本社交平台,占据了关键地位。其话题热度波动反映了社会舆论的趋势,这一现象既是公众关注的焦点,也是企业研究的重点。
微博舆情监测的必要性
微博汇集了众多不同群体的声音。数据表明,微博上每天产生的话题数量众多。企业若想了解消费者情绪的变化,进行舆情监控是至关重要的。以某品牌为例,在新品发布时未进行微博舆情监控,导致大量负面评价未能及时应对。通过舆情监控,企业可以提前感知市场变化,防止危机加剧。微博上不同群体的发声不容忽视,从明星粉丝到各类兴趣小组,都构成了潜在的舆论力量。
个人通过关注微博舆情,可以洞察社会发展趋势。这使普通民众得以掌握社会发展的成就与不足。例如,在地方民生政策实施过程中,微博舆情能够揭示民众最直接的声音。
相关数据的重要价值
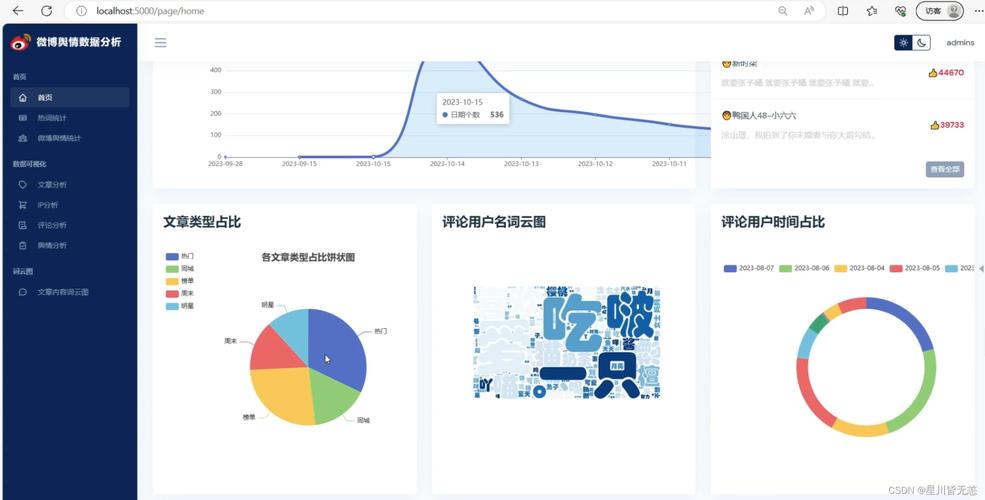
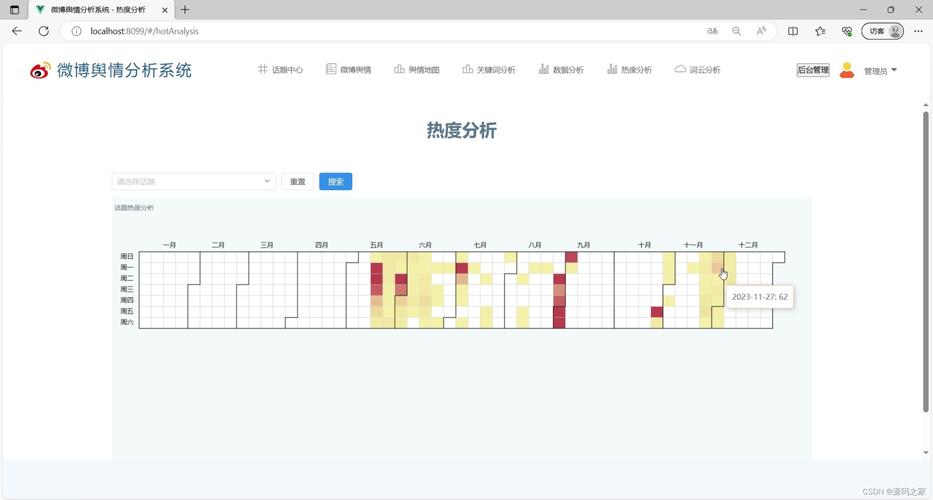
微博舆情的基础包括话题热度、讨论量及关联评论数据。这些数据展现了话题在用户中的关注度,其中热度越高,关注人数越多。当某一社会事件在微博的话题热度达到最高点,通常也是社会关注度最强烈的时候。讨论量直接展示了用户参与的数量,以某公益活动为例,其讨论量从少到多,反映了活动影响力的变化。
评论内容展现了公众意见的丰富性,涵盖了积极的认可、消极的批评以及合理的建议等不同类型。以一部新电影上映为例,微博上的讨论既包含了对故事情节的喜爱,也出现了对演员表演的疑问,这些观点汇总后,对电影未来的票房走向产生了微妙的作用。
爬虫技术的地位
爬虫技术在获取微博话题热度数据方面发挥着至关重要的作用。随着技术的持续进步,爬虫在大数据领域展现出其快速和精准的数据定位能力。以Python的Scrapy框架为例,该框架凭借其高效的抓取性能和高度的灵活性,在数据采集领域表现出色。通过设定恰当的爬虫规则,可以精确地搜集微博中特定话题的相关数据。
新型算法及高级编码技术显著增强了爬虫性能。经过优化的爬虫算法在处理大量微博话题热度数据时,能有效降低资源消耗并提升抓取效率。专业爬虫工程师在复杂数据环境中确保爬虫稳定运作。
实际搭建舆情监控系统的步骤
首先需明确讨论的主题。依据具体需求,在微博上挑选与业务紧密相关的话题,例如,企业可能关注其产品特性,如某手机品牌对手机性能、设计等议题的关注。接下来,实施数据搜集环节,通过爬虫技术依照既定标准,搜集与选定话题相关的信息。
数据清洗是第三阶段的任务,考虑到从微博平台收集的数据可能包含杂质,比如无效链接和重复内容。这一步骤对于保证分析结果的准确性至关重要。以某汽车品牌的舆情监控为例,未经清洗的数据在分析时往往存在偏差,而经过清洗后,分析结果才能更贴近真实情况。接下来是第四步,即数据分析和可视化,这一过程可以利用Python的Pandas和Matplotlib等工具进行深入挖掘和直观呈现。
代码示例深度解读
Python因其简洁性及丰富的库资源,成为爬虫领域的热门工具。以BeautifulSoup库为例,它被用于解析网页结构,以提取微博话题信息。代码执行过程中,每行代码都承载着具体的功能。例如,某行代码专门用于获取与网页链接对应的HTML文档,这一步骤为后续数据提取奠定了基础。
该代码行主要功能在于对HTML文档中的特定元素进行搜索,这一过程对于精确锁定话题热度数值等关键数据至关重要。在编写代码时,必须考虑到微博网页结构可能发生的变动。鉴于微博平台可能随时对网页样式和布局进行更新,编写的代码必须具备足够的灵活性,以适应这些变化。
面临的挑战与未来展望
隐私保护构成一大挑战,微博用户的个人信息亟需得到妥善防护。爬虫在抓取数据过程中,若操作不当,可能导致隐私信息过度收集,从而侵犯用户隐私权。此外,爬虫还可能遇到微博的反爬虫策略,例如IP封禁等。技术人员需持续提升对抗反爬虫技术的技能。
展望未来,大数据与人工智能技术的持续进步预示着舆情监控将迈向智能化新阶段。数据整合与分析能力将显著提升,微博话题热度的监测将更加精确和实时。
各位读者,在数字化时代,我们如何能在维护隐私的同时,有效实施舆情监控?期待您的热情参与,发表见解,为文章点赞及转发。
买微博热一要多少钱
,
微博买热度多少钱
相关帖子
•
2024年品牌营销热点:短剧如何成为品牌必争之地?
•
任正非谈时代进步与何炅48岁生日冷清背后的娱乐圈变迁
•
女孩们的追星真相:同人文、钱和中年男明星的魅力解析
•
微博热度哪里买 冰封侠:时空行者官微与甄子丹激烈对峙,真相扑朔迷离引热议
•
揭秘国内电视剧行业乱象:从抄袭剧本到替身表演,揭露假电视剧的诞生过程
•
郑爽微博有偿回答再上热搜,粉丝提醒隐身避热度引热议
•
微博下线明星势力榜,倡导理智追星,娱乐圈迎来新变革
•
雷军三招低成本营销组合拳: 人设反差成焦点
•
微博如何买热度 德州市推出提振消费五大工程实施方案 助力消费升级与经济发展
•
李晟热度狂飙登断层第一,空降浪姐直播间引发热潮
回复
使用道具
举报
返回列表
发新帖
高级模式
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
立即注册
本版积分规则
发表回复
回帖后跳转到最后一页
doudoow
1838
主题
1839
帖子
6388
积分
论坛元老
论坛元老, 积分 6388, 距离下一级还需 9993611 积分
论坛元老, 积分 6388, 距离下一级还需 9993611 积分
积分
6388
加好友
发消息
回复楼主
返回列表
QQ教程篇
网络分享
绿色软件
虚拟商品
影视资源
VIP项目
网络资源
软件下载
有奖活动
新闻资讯
图文推荐
热门排行
1
小红书种草推广方法及适用人群,助你制定营销计划
2
小红书创作者涨粉难?关键在于建立用户信任
3
关注和增长:衡量账号长期影响力的重要指标及优化策略
4
短视频运营领域新人如何调整自己?这些要点助你钱途更广
5
抖音播放量收入规则详解:如何通过播放量赚钱
6
如何利用小红书指数进行数据分析?快来了解一下
7
AI 文稿对账号影响不大,关键在于内容和商品转化
8
小红书关闭小绿洲,电商之路何去何从?对消费者有何影响?