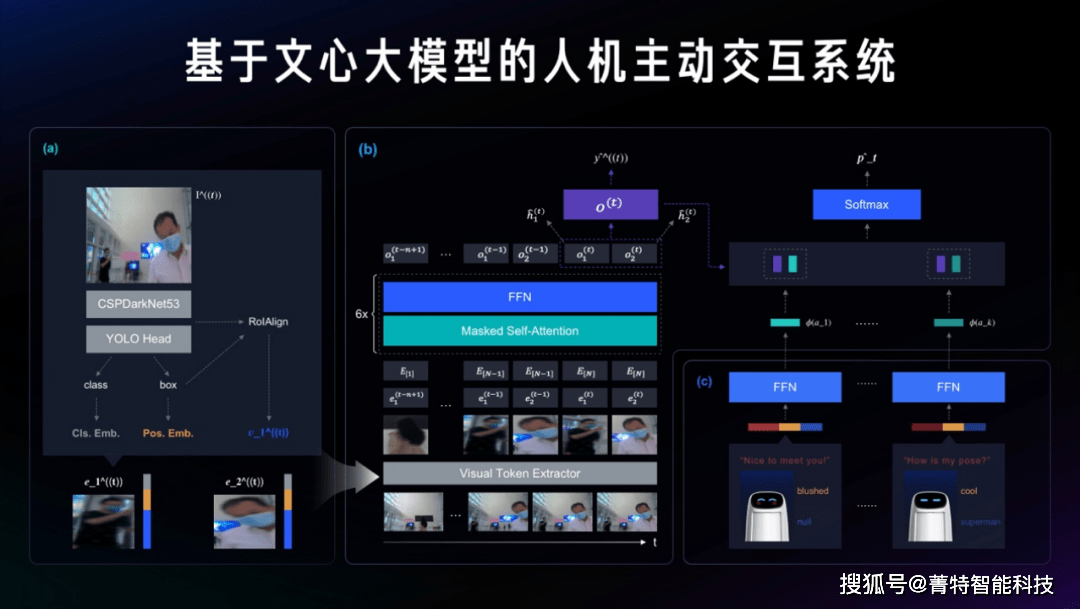
为了使得机器人能够更加理解场景的细节,带来更加智能、友好、和自然化的交互体验,百度提出了全新的“基于视觉记号和 Transformer 模型的人机主动交互系统”(TransFormer with Visual Tokens for Human-Robot Interaction,简称 TFVT-HRI)。这套系统不仅能观察场景主动发起交互和引导,其交互的动作更是包含千余种多模态动作,使其能够像人类一样表现出自然的主动问候。
独立样本 T 检验(Independent-Samples T Test)结果显示:两组被试在效价(t(28)=1.218,p=0.233>0.05)和唤醒度(t(28)=1.906,p=0.067>0.05)均不存在显著差异。将 Valence-Arousal 数据映射到社会心理学中常用的 Russel 情感极坐标模型,可以发现两种交互系统都能给用户带来偏向『激动』(EXCITED)的正向情绪。
虽然两种模式唤起的用户情绪无显著差异,但在其他主观指标上,两种交互系统差异明显。Levene’ Test 表明,除了“智能的”之外,其他变量方差齐性(homogeneity of variance)的假设成立,因此我们对“整体舒适度”、“自然的”、“友好的”进行了独立样本 T 检验,对“智能的”进行了 t'检验。 结果显示,两组被试对“整体舒适度”(t(28)=2.141,p=0.041