你也许也喜欢:
日志文件分析应该是每个谷歌 SEO 专业人士工具带的一部分,但大多数谷歌 SEO 从未进行过。这意味着大多数谷歌 SEO 都错过了常规抓取工具无法产生的独特且宝贵的见解。
让我们揭开日志文件分析的神秘面纱,让它不那么令人生畏。如果您对日志文件的奇妙世界以及它们可以为您的站点审核带来什么感兴趣,那么本指南绝对适合您。
什么是日志文件?
日志文件是包含有关谁和什么向您的网站服务器发出请求的详细日志的文件。每次机器人向您的站点发出请求时,数据(例如时间、日期、IP 地址、用户代理等)都会存储在此日志中。这些有价值的数据允许任何谷歌 SEO 找出 Googlebot 和其他爬虫在你的网站上做了什么。与 Screaming Frog google SEO Spider 等常规爬行不同,这是真实世界的数据,而不是对您的网站如何被爬行的估计。它准确概述了您的网站是如何被抓取的。
拥有这些准确的数据可以帮助您确定抓取预算浪费的区域,轻松找到访问错误,了解您的 google SEO 工作如何影响抓取等等。最好的部分是,在大多数情况下,您可以使用简单的电子表格软件来完成此操作。
在本指南中,我们将重点关注 Excel 来执行日志文件分析,但我也会讨论其他工具,例如 Screaming Frog 不太知名的日志文件分析器,它可以通过帮助您管理来使工作更容易和更快更大的数据集。
注意:拥有除 Excel 以外的任何软件都不是遵循本指南或接触日志文件的必要条件。
如何打开日志文件将 .log 重命名为 .csv
当您获得扩展名为 .log 的日志文件时,实际上就像将文件扩展名重命名为 .csv 并在电子表格软件中打开文件一样简单。如果您想编辑这些文件,请记住将您的操作系统设置为显示文件扩展名。
如何打开拆分日志文件
日志文件可以放在一个大日志或多个文件中,具体取决于您站点的服务器配置。一些服务器将使用服务器负载平衡来在服务器池或服务器场之间分配流量,从而导致日志文件被拆分。好消息是合并真的很容易,你可以使用这三种方法之一来合并它们,然后正常打开它们:
然后运行以下命令:
复制 *.log mylogfiles.csv
您现在可以打开 mylogfile.csv,它将包含您所有的日志数据。或者如果您是 Mac 用户,请先使用 cd 命令转到您的日志文件目录:
cd 文档/MyLogFiles/
然后,使用 cat 或 concatenate 命令连接你的文件:
cat *.log > mylogfiles.csv
2) 使用免费工具Log File Merge,合并所有日志文件,然后将文件扩展名编辑为.csv 并正常打开。
3) 使用尖叫青蛙日志文件分析器打开日志文件,就像拖放日志文件一样简单:
拆分字符串
(请注意:如果您使用的是 Screaming Frog 的日志文件分析器,则不需要此步骤)
打开日志文件后,您将需要将每个单元格中的繁琐文本拆分成列,以便以后更容易排序。
Excel 的文本到列功能在这里派上用场,就像选择所有填充的单元格 (Ctrl / Cmd + A) 并转到 Excel > 数据 > 文本到列并选择“分隔符”选项一样简单,分隔符是一个空间字符。
将其分开后,您可能还想按时间和日期排序 — 您可以在时间和日期戳列中执行此操作,通常使用“:”冒号分隔符分隔数据。
您的文件应类似于以下文件:
如前所述,如果您的日志文件看起来不完全相同,请不要担心——不同的日志文件具有不同的格式。只要您拥有基本数据(时间和日期、URL、用户代理等),就可以开始了!
了解日志文件
现在您的日志文件已准备好进行分析,我们可以深入研究并开始了解我们的数据。具有多个不同数据点的日志文件可以采用多种格式,但它们通常包括以下内容:
如果您对细节感兴趣,可以在下面找到有关常见格式的更多详细信息:
如何快速揭示抓取预算浪费
快速回顾一下,抓取预算是搜索引擎在每次访问您的网站时抓取的页面数。许多因素会影响抓取预算,包括链接资产或域权限、站点速度等。通过日志文件分析,我们将能够看到您的网站有什么样的抓取预算,以及哪些地方存在导致抓取预算浪费的问题。
理想情况下,我们希望为爬虫提供最高效的爬行体验。不应将抓取浪费在低价值页面和 URL 上,并且优先页面(例如产品页面)不应具有较慢的索引和抓取速度,因为网站有太多无用的页面。游戏的名称是抓取预算保护,良好的抓取预算转换会带来更好的有机搜索性能。
查看用户代理抓取的 URL
查看网站 URL 被抓取的频率可以快速揭示搜索引擎将时间用于抓取的位置。
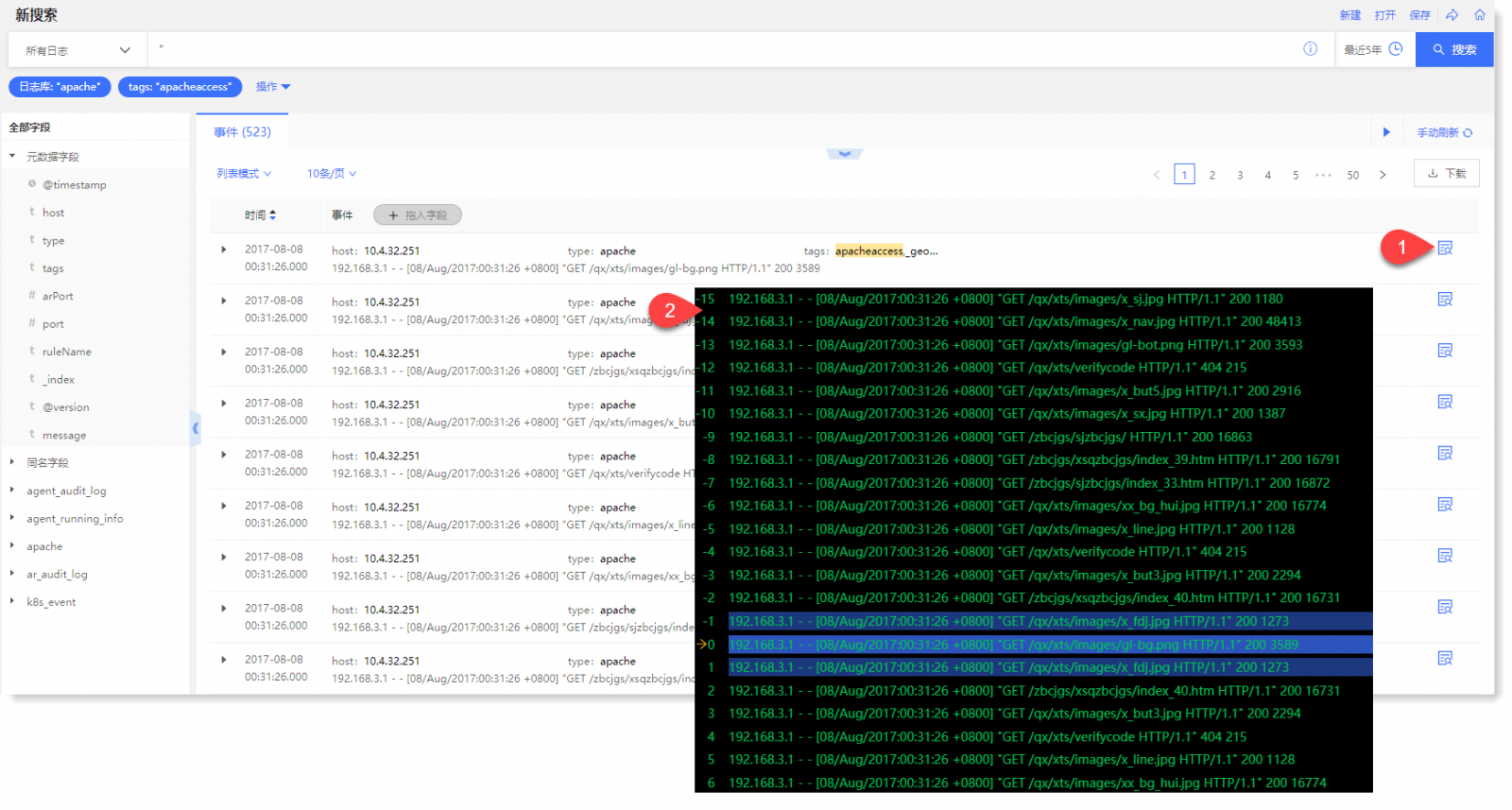
如果您有兴趣查看单个用户代理的行为,这很简单,只需过滤掉 excel 中的相关列即可。在这种情况下,使用 WC3 格式的日志文件,我通过 Googlebot 过滤 cs(User-Agent) 列:
然后过滤 URI 列以显示 Googlebot 抓取此示例站点主页的次数:
这是通过 URI 词干查看单个用户代理是否存在任何问题区域的快速方法。您可以更进一步,查看 URI 词干列的过滤选项,在本例中为 cs-uri-stem:
从这个基本菜单中,我们可以看到正在抓取哪些 URL,包括资源文件,以快速识别任何有问题的 URL(例如,不应抓取的参数化 URL)。
您还可以使用数据透视表进行更广泛的分析。要获取特定用户代理抓取特定 URL 的次数,请选择整个表 (Ctrl/cmd + A),转到插入 > 数据透视表,然后使用以下选项:
我们所做的只是按用户代理进行过滤,将 URL 词干作为行,然后计算每个用户代理出现的次数。
在我的示例日志文件中,我得到了以下信息:
然后,为了按特定的用户代理进行过滤,我单击了包含“(全部)”的单元格上的下拉图标,并选择了 Googlebot:
了解哪些不同的机器人在爬行,移动机器人与桌面机器人的爬行方式有何不同,以及爬行最多的地方可以帮助您立即了解哪里存在爬行预算浪费以及网站的哪些区域需要改进。
查找低价值附加网址
不应将抓取预算浪费在低附加值的 URL 上,这通常是由会话 ID、无限抓取空间和分面导航引起的。
为此,请返回您的日志文件,并按包含“?”的 URL 进行过滤。或 URL 列中的问号符号(包含 URL 词干)。要在 Excel 中执行此操作,请记住使用“~?” 或波浪号问号,如下所示:
一个“?” 或问号,如自动过滤器窗口中所述,代表任何单个字符,因此添加波浪号就像转义字符,并确保过滤掉问号符号本身。
那不是很容易吗?
查找重复的网址
重复的 URL 可能会浪费抓取预算和谷歌 SEO 的大问题,但找到它们可能会很痛苦。URL 有时可能会有轻微的变体(例如 URL 的尾部斜线与非尾部斜线版本)。
最终,查找重复 URL 的最佳方式也是最不有趣的方式——您必须按网站 URL 词干按字母顺序排序并手动观察它。
您可以找到同一 URL 的尾随和非尾随斜杠版本的一种方法是在另一列中使用 SUBSTITUTE 函数并使用它来删除所有正斜杠:
=SUBSTITUTE(C2, “/”, “”)
在我的例子中,目标单元格是 C2,因为词干数据位于第三列。
然后,使用条件格式来识别重复值并突出显示它们。
然而,不幸的是,目测是目前最好的方法。
查看子目录的抓取频率
找出哪些子目录被抓取最多是另一种揭示抓取预算浪费的快速方法。请记住,仅仅因为客户的博客从未获得过一个反向链接并且一年仅从企业主的祖母那里获得三个视图并不意味着您应该认为它是抓取预算浪费——内部链接结构应该在整个网站上始终如一从客户的角度来看,该内容可能有充分的理由。
要按子目录级别找出抓取频率,您需要主要观察它,但以下公式可以提供帮助:
=IF(RIGHT(C2,1)=”/”,SUM(LEN(C2)-LEN(SUBSTITUTE(C2,”/”,””)))/LEN(“/”)+SUM(LEN(C2) -LEN(SUBSTITUTE(C2,”=”,””)))/LEN(“=”)-2, SUM(LEN(C2)-LEN(SUBSTITUTE(C2,”/”,””)))/LEN (“/”)+SUM(LEN(C2)-LEN(SUBSTITUTE(C2,”=”,””)))/LEN(“=”)-1)
上面的公式看起来有点傻,但它所做的只是检查是否有尾部斜线,并根据答案计算尾部斜线的数量,然后从数字中减去 2 或 1。如果您使用 RIGHT 公式从您的 URL 列表中删除所有尾部斜杠,则可以缩短该公式——但谁有时间。您剩下的是子目录计数(从 0 开始作为第一个子目录)。
将 C2 替换为第一个 URL 词干/URL 单元格,然后将公式复制到整个列表中以使其正常工作。
确保将所有 C2 替换为适当的起始单元格,然后按从小到大对新的子目录计数列进行排序,以按逻辑顺序获得良好的文件夹列表,或轻松按子目录级别进行过滤。例如,如下面的截图所示:
上图是按级别排序的子目录。
上图是按深度排序的子目录。
如果您不处理很多 URL,您可以简单地按字母顺序对 URL 进行排序,但这样您将无法获得子目录计数过滤,这对于较大的站点来说可能要快得多。
按内容类型查看抓取频率
找出哪些内容正在被抓取,或者是否有任何内容类型占用了抓取预算,这是发现抓取预算浪费的一个很好的检查。频繁抓取不必要或低优先级的 CSS 和 JS 文件,或者如果您尝试优化图像搜索,抓取图像是如何发生的,很容易通过这种策略被发现。
在 Excel 中,按内容类型查看爬网频率就像使用 Ends With 过滤选项按 URL 或 URI 词干过滤一样简单。
快速提示:您还可以使用“不结束于”过滤器并使用 .html 扩展名来查看非 HTML 页面文件是如何被抓取的——总是值得检查以防抓取预算浪费在不必要的 js 或 css 文件上,或者甚至图像和图像变体(看着你的 WordPress)。另外,请记住,如果您的网站有尾部和非尾部斜杠 URL,请使用带过滤功能的“或”运算符将其考虑在内。
监视机器人:了解网站抓取行为
日志文件分析让我们了解机器人的行为方式,让我们了解它们的优先顺序。不同的机器人在不同情况下的行为如何?有了这些知识,您不仅可以加深对 google SEO 和爬行的理解,还可以让您在理解站点架构有效性方面有一个巨大的飞跃。
查看最多和最少被抓取的网址
此策略之前已通过用户代理查看已抓取的 URL 进行了改进,但速度更快。
在 Excel 中,选择表格中的一个单元格,然后单击“插入”>“数据透视表”,确保选择包含必要的列(在本例中为 URL 或 URI 主干和用户代理),然后单击“确定”。
创建数据透视表后,将行设置为 URL 或 URI 词干,并将求和值设置为用户代理。
从那里,您可以右键单击用户代理列并按抓取次数从大到小对 URL 进行排序:
现在您将拥有一张很棒的表格,可以从中制作图表或快速查看并查找任何有问题的区域:
查看此数据时要问自己的一个问题是:您或客户是否希望抓取这些页面?多常?频繁抓取并不一定意味着更好的结果,但它可以表明 Google 和其他内容用户代理最优先考虑的内容。
每天、每周或每月的抓取频率
检查抓取活动以确定在一段时间内失去可见性的问题,在谷歌更新后或在紧急情况下可以告诉你问题可能在哪里。这就像选择“日期”列一样简单,确保该列是“日期”格式类型,然后在日期列上使用日期过滤选项。如果您要分析整周,只需选择具有可用过滤选项的相应日期。
按指令抓取频率
了解谷歌正在遵循哪些指令(例如,如果您在 robots.txt 中使用禁止甚至无索引指令)对于任何谷歌搜索引擎优化审计或活动都是必不可少的。例如,如果站点使用带有分面导航 URL 的禁止,您需要确保遵守这些规定。如果不是,请推荐更好的解决方案,例如元机器人标签等页面指令。
要按指令查看抓取频率,您需要将抓取报告与日志文件分析相结合。
(警告:我们将使用 VLOOKUP,但它实际上并不像人们想象的那么复杂)
要获取组合数据,请执行以下操作: |