本站资源限时全部免费
开启辅助访问
切换到窄版
登录
立即注册
首页
论坛
前线论坛
频道
软件
插件
Plugin
网课
搜索
搜索
每日签到
本版
文章
帖子
用户
QQ前线乐园
»
论坛
›
前线大厅
›
QQ教程篇
›
Python定时爬取微博热搜榜与热评的完整实现方法及代理IP ...
返回列表
发新帖
Python定时爬取微博热搜榜与热评的完整实现方法及代理IP应用
[复制链接]
730
|
0
|
2024-12-27 09:21:13
|
显示全部楼层
|
阅读模式
在闲暇的办公时刻,许多人习惯于通过浏览微博热搜来消磨时间,然而,职场环境通常不允许此类行为。这种情况下,人们渴望了解热点信息,却又难以直接获取。为此,本文将介绍一种解决方案,即利用Python技术抓取微博热搜排行榜。
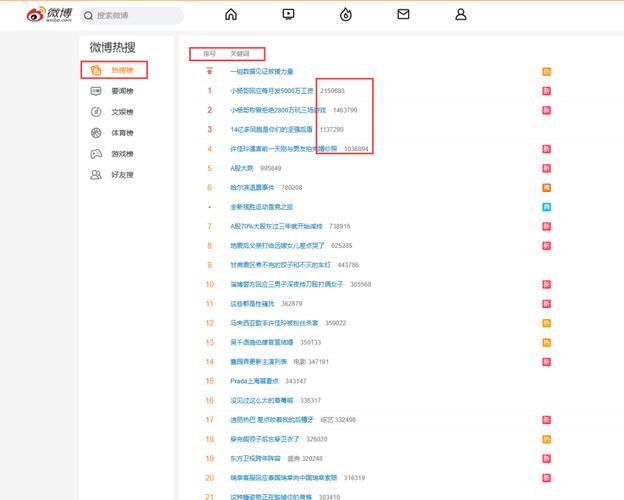
微博热搜的吸引力
微博热搜如同社会的一面映照,揭示了当前最受关注的话题和公众的关注焦点。众多新闻、娱乐和社会事件每日在热搜上广泛传播。众多用户渴望迅速获取这些资讯,据不完全统计,微博日活跃用户数超过两亿,其中不乏对热搜内容高度关注的群体。此外,热搜还对公众舆论走向产生显著影响。但值得注意的是,在工作时段浏览热搜可能会降低工作效率。
在工作之余,许多人倾向于快速查看热搜中的趣味话题。然而,在部分办公场所,手机使用受到限制,这无疑成为了一个困扰。
Python在数据采集中的作用
Python以其简洁的特性及丰富的第三方库支持,在数据采集领域发挥着关键作用。众多开发者对其情有独钟。尤其在应对微博热搜数据的采集任务时,Python的易用性表现得尤为突出。它能高效地从微博服务器端抓取所需信息。
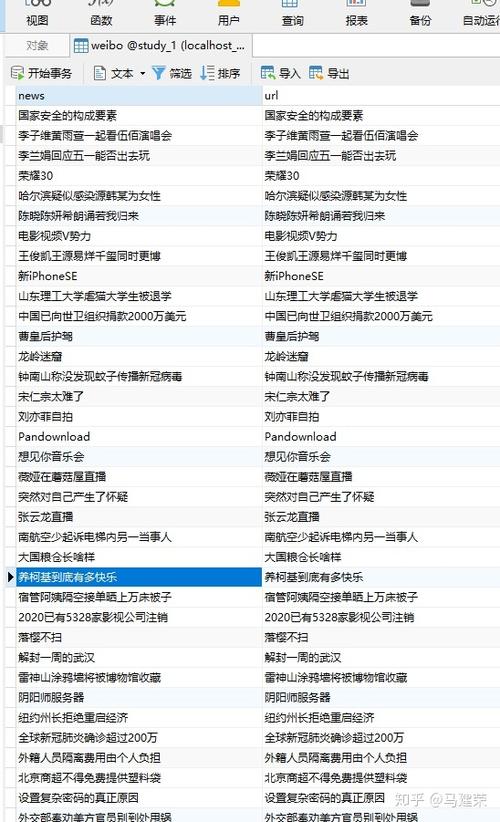
以热搜首页链接为参照,运用Python技术可收集到500条数据。这一数据量对于掌握热搜动态已足够充分。此外,Python的代码结构清晰,使得开发者能够快速掌握并编写用于采集微博热搜信息的程序。
采集代码的编写
需先识别微博的排名、热度、标题及详情页的链接。这些信息是后续数据采集的基石。正如建造高楼大厦离不开坚实的地基。在编写代码阶段,可通过发送请求来搜集热门内容。尽管实现基本功能代码相对简单,但采集过程仍需谨慎操作。
在基本代码编写过程中,必须精确地依据微博网页的布局定位数据存储的具体位置。若未能做到这一点,可能会获取到无效或错误的数据,进而对数据采集的整体效果产生不利影响。
可能遇到的阻碍
采集过程中并非毫无阻碍。可能会遇到网站封禁IP的问题。这主要是因为爬虫活动常被网站视为异常访问。频繁向微博服务器发送请求,网站出于安全考虑,可能会采取封禁IP的措施。
据调查,部分小型爬虫在短时间内频繁发起请求,其中不少已被限制。鉴于此,在抓取微博热门话题时,必须对此现象给予关注。
使用代理IP的必要性
代理IP充当了一道防护屏障。亿牛云提供的代理IP在示例中有效解决了相关问题。借助代理IP,用户能隐匿其真实IP地址,降低被封禁的风险;同时,它还能显著提升数据采集的效率。
采用代理IP技术,整体数据采集效率显著增强。这主要体现在两个方面:一是采集速度不会因请求频繁而降低,二是数据获取的稳定性得到显著提高。
采集实例的总结
本示例对Python实现微博热搜定时爬取的方法进行了介绍。此方法适用于那些希望在忙碌工作之余了解微博热搜动态,但受限于条件的人群。通过本示例,用户能够获取热搜信息,满足对热点话题的探知欲望。关于更多Python爬取微博热搜的详细内容,我们将在后续分享中继续探讨学习。
若您希望在办公期间把握微博热门话题的同时遵守相关规定,是否考虑采用此Python数据抓取技术?期待各位读者积极为本文点赞、转发,并在评论区积极参与讨论。
微博话题热搜怎么买
,
微博热搜和话题的作用
相关帖子
•
小米、特斯拉跨界周边撬流量:社交营销反哺核心业务,如小米的那些操作
•
微博热搜可购买:揭秘购买手段、陷阱与利用攻略
•
小米特斯拉跨界周边撬动品牌流量,限量社交营销反哺核心业务
•
椰树集团承诺100%原汁椰子水 低价椰子水质量引消费者担忧
•
微博热搜背后藏着啥商业模式?买热搜真能获高效回报?
•
微博热搜购买途径多样:官方、第三方、明星粉丝团,各有优劣
•
2009 - 2014年网民增长一倍背景下微博胜利的原因
•
DeepSeek国产AI大模型2025年春节前夕引发全民热议与社交平台价值重构
•
猪头左拆爆红淘宝店铺,微博热搜后订单暴增1000%的网红创业故事
回复
使用道具
举报
返回列表
发新帖
高级模式
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
立即注册
本版积分规则
发表回复
回帖后跳转到最后一页
enrl305
1860
主题
1861
帖子
6454
积分
论坛元老
论坛元老, 积分 6454, 距离下一级还需 9993545 积分
论坛元老, 积分 6454, 距离下一级还需 9993545 积分
积分
6454
加好友
发消息
回复楼主
返回列表
QQ教程篇
网络分享
绿色软件
虚拟商品
影视资源
VIP项目
网络资源
软件下载
有奖活动
新闻资讯
图文推荐
热门排行
1
小红书种草推广方法及适用人群,助你制定营销计划
2
小红书创作者涨粉难?关键在于建立用户信任
3
关注和增长:衡量账号长期影响力的重要指标及优化策略
4
短视频运营领域新人如何调整自己?这些要点助你钱途更广
5
抖音播放量收入规则详解:如何通过播放量赚钱
6
如何利用小红书指数进行数据分析?快来了解一下
7
AI 文稿对账号影响不大,关键在于内容和商品转化
8
小红书关闭小绿洲,电商之路何去何从?对消费者有何影响?