本站资源限时全部免费
开启辅助访问
切换到窄版
登录
立即注册
首页
论坛
前线论坛
频道
软件
插件
Plugin
网课
搜索
搜索
每日签到
本版
文章
帖子
用户
QQ前线乐园
»
论坛
›
前线大厅
›
QQ教程篇
›
Python爬取小红书关键词笔记评论:开源工具项目详情 ...
返回列表
发新帖
Python爬取小红书关键词笔记评论:开源工具项目详情
[复制链接]
716
|
0
|
2025-1-30 19:19:07
|
显示全部楼层
|
阅读模式
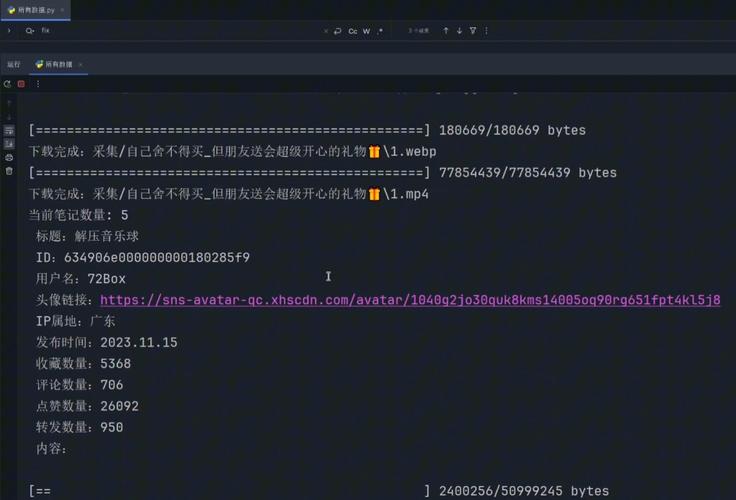
在社交网络盛行的当下,小红书以丰富的内容推动了众多潮流。然而,如何深入挖掘这些内容中的信息成为一大挑战。一款Python智能爬虫工具的出现,为解决这一难题提供了强有力的支持,其吸引力不言而喻。
项目背景概述
近期,小红书用户数量急剧增长。该平台已成为时尚、美妆和生活等领域潮流信息的集中展示区。在众多信息中,蕴藏着大量有待挖掘的宝贵数据。据2023年的一项调查报告显示,超过一半的品牌及营销从业者对深入分析小红书数据抱有强烈愿望。为此,一款Python爬虫工具应运而生。该工具的主要开发者系一名数据科技公司工程师,其初衷旨在满足市场对小红书数据挖掘的需求。
该工具有效突破了传统数据收集的障碍。过去需耗时数日乃至数周的人工收集小红书笔记及评论,现在可在极短时间内大量获取,显著提升了数据采集的效率。
核心框架解析
该Python爬虫工具采用的技术架构确保了其高效性能。以requests库为例,它在众多数据采集任务中被广泛应用,能够迅速向小红书服务器发起请求以抓取网页信息。此外,beautifulsoup4库则扮演着一种精确的解码角色,能够将搜集到的杂乱网页数据转换成便于分析的格式。
与此同时,jieba分词库在处理小红书大量中文内容方面展现出显著功效。根据2022年数据研究,该分词库在众多中国本土文本处理任务中的准确率超过90%。它能够精确分割中文文本,确保数据处理精确无误。此外,wordcloud库的整合使得生成的词云图直观易懂,用户可迅速识别关键词及其权重等关键信息。
功能特性呈现
该工具的核心优势在于其能够借助特定关键词,精确锁定小红书平台上的相关笔记与评论。比如,设定“时尚搭配”作为关键词,系统便能筛选出所有相关内容。这种高精准度在市场调研领域具有极高的实用价值。
该工具操作简便。即便缺乏丰富编程背景的人,经过基础学习后也能熟练运用。据最新测试结果显示,新手仅需大约6小时的学习时间,即可初步掌握使用该工具进行基本的数据检索操作。此举显著降低了使用门槛,使得更多人能够使用该工具。
广泛应用范围
品牌监控功能效果显著。比如,当一家新美妆品牌踏入市场,该工具可协助监测小红书用户对其的评价,从而迅速调整营销方案。以2023年进入中国市场的某小众美妆品牌为例,借助该工具的数据分析,该品牌在短短一个月内便优化了产品推广手段,显著提高了品牌知名度。
在市场研究领域,该工具具有广阔的应用前景。人口学研究者曾运用此工具搜集母婴话题的评论,深入探究年轻妈妈的消费心态,并积累了大量原始数据。
项目合规性提醒
使用此工具时,需确保操作符合规定。尽管该工具开源,但所采集的数据源自小红书。小红书明确要求保护用户隐私并遵守平台规则。2021年,因不当使用爬虫侵犯平台权益的事件受到处罚。因此,用户必须遵守法律法规和平台规定,合法合规地进行数据采集。
操作时需确保数据使用合理,严禁无度爬取信息,亦不得将个人隐私数据用于非法用途。
项目发展展望
该工具具有广阔的发展潜力。随着市场对数据挖掘需求的持续增长,其将持续进行优化升级。开发团队计划在不久的将来引入新功能,例如评论的深度语义分析。此外,他们还希望吸引更多人士加入开源项目,共同分享使用体验和改进意见,以提升工具的完整性。目前,已有部分学校的社团表达了对参与项目改进与开发的兴趣。
您是否对这款能够追踪小红书流行趋势的Python自动化抓取工具有了更新的了解?我们诚挚邀请您在评论区发表您的见解,同时,请不要忘记为本文点赞及分享。
小红书买书
,
小红热门买书是真的吗
,
小红热门买书是正版吗
相关帖子
•
小红书推广上热门秘籍:精准定位受众+关键词布局+日引流1000+技巧
•
探索小红书运营之道:精准定位、优质内容与引流技巧
•
蒋方舟与Durov谈社交网络逃离:为何主动脱离互联网成为新趋势
•
再见爱人4热度爆棚:全端热搜超905条且登顶豆瓣实时热力榜首
•
小红书贵替话题:美妆个护热度高,护肤需求新走向
•
小红书推广上热门的技巧:关键词布局与笔记质量
•
小红书推广上热门技巧:关键词布局与笔记质量
•
小红书新手看过来!教你购买置顶作品提升曝光率
回复
使用道具
举报
返回列表
发新帖
高级模式
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
立即注册
本版积分规则
发表回复
回帖后跳转到最后一页
安若
1778
主题
1778
帖子
6190
积分
论坛元老
论坛元老, 积分 6190, 距离下一级还需 9993809 积分
论坛元老, 积分 6190, 距离下一级还需 9993809 积分
积分
6190
加好友
发消息
回复楼主
返回列表
QQ教程篇
网络分享
绿色软件
虚拟商品
影视资源
VIP项目
网络资源
软件下载
有奖活动
新闻资讯
图文推荐
热门排行
1
小红书种草推广方法及适用人群,助你制定营销计划
2
小红书创作者涨粉难?关键在于建立用户信任
3
关注和增长:衡量账号长期影响力的重要指标及优化策略
4
短视频运营领域新人如何调整自己?这些要点助你钱途更广
5
抖音播放量收入规则详解:如何通过播放量赚钱
6
如何利用小红书指数进行数据分析?快来了解一下
7
AI 文稿对账号影响不大,关键在于内容和商品转化
8
小红书关闭小绿洲,电商之路何去何从?对消费者有何影响?