在当前信息量激增的时代背景下,微博热搜榜扮演着信息汇聚的核心角色。了解如何获取相关信息,包括爬取时间、序号、关键词和热度等,对于数据分析师和普通网民来说都具有重要意义。这一过程宛如打开了一扇通往热门话题宝藏的门户。
网页分析基础
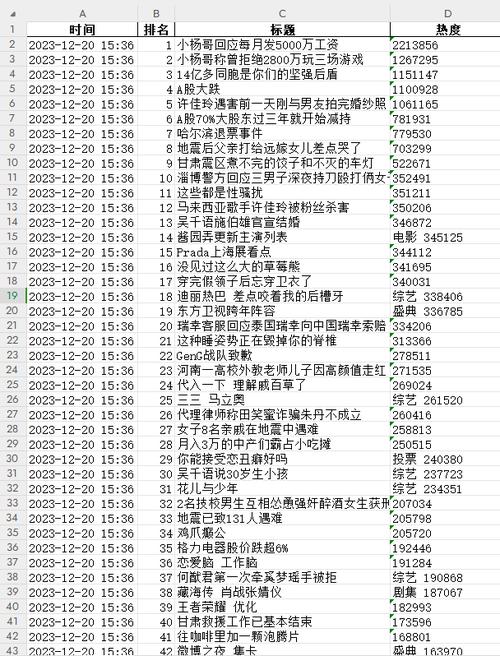
微博热搜榜的网址是我们追踪信息的核心渠道。该榜单信息持续更新,每次展示50个热门话题。以某月某日上午十点为例,榜单内容已焕然一新。在审查网页时,我们如同探险者。以“小杨哥发工资回应”等具体热搜为例进行搜索,可以查看到相关热度数据和链接。由此可见,热搜信息在网页上以表格形式呈现,这为我们后续的数据抓取工作指明了方向。这就像在迷宫中发现了关键线索,是至关重要的进展。
从技术角度分析,此类网页布局使我们能够精确识别数据位置。我们能够迅速掌握各热搜在网页结构中的具体位置,并明确需从哪些代码片段中提取所需信息。
模块的导入很重要
进行Python微博热搜数据抓取操作,导入相应模块是初始阶段的关键。这相当于建筑房屋前的地基工作。以requests模块为例,它在获取网页数据上扮演着至关重要的角色。至2023年初,众多用户在执行这类数据抓取任务时,均会优先检查该模块是否已正确引入。
此外,诸如beautifulsoup等库在处理HTML与XML文件方面发挥着关键作用,尤其是在解析网页获取的HTML数据时。准确导入这些库对于保证后续工作的流畅至关重要。若遗漏或误导入,就如同建筑缺少了关键建材,难以完成建设。
请求网页数据
模块支持使得获取微博网页数据成为可能。此过程与向数据库提交订单相似。每次数据请求均发生在特定时刻。比如,每天下午3点左右,数据流量达到高峰,此时获取数据需妥善应对潜在的负载挑战。
准确编写指令有助于获取详尽的网页原始信息。若数据获取不完整或失败,可能是请求参数或方法存在错误。这如同快递员未能获取到准确的收货地址。
解析数据信息
获取网页数据后,首要任务是进行数据解析。这一过程相当于对混乱的宝藏进行有序归类。我们需要从无序的数据中筛选出爬取时间、序号、关键词及热度等关键信息。
对于微博热搜榜以表格形式呈现的数据,我们运用了恰当的解析手段。例如,通过之前导入的模块特定功能,逐一识别各个单元格所对应的数据单元。若遇到因网页格式更新导致解析困难的情况,就如同遇到更换了新密码的密码锁,令人感到困扰。
<p><pre> <code class="language-python">import time
import requests
import pandas as pd</code></pre></p>
结果的保存功课
完成前期步骤后,需对所得数据进行存档。这一步骤至关重要,犹如农夫妥善保管丰收的谷物。无论选择将数据保存为本地文本文件,抑或存入数据库,均需依据数据量及使用环境来定。
<p><pre> <code class="language-python">headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36',
}
url = 'https://s.weibo.com/top/summary'
df = getweibodata(url,headers)</code></pre></p>
调查结果显示,今年7月,众多数据爬取者因未实施有效数据保存措施,遭遇了数据丢失问题。同时,不同的数据保存方法显著影响了后续的数据检索与处理效率。
实际应用与意义
<p><pre> <code class="language-python">time_mow = time.strftime("%Y-%m-%d %H:%M", time.localtime())
df['时间'] = [time_mow] * df.shape[0]
df['排名'] = df['序号'].apply(int)
df['标题'] = df['关键词'].str.split(' ', expand=True)[0]
df['热度'] = df['关键词'].str.split(' ', expand=True)[1]</code></pre></p>
利用Python工具抓取微博热搜榜单数据具有重要的现实价值。对于专注于社交媒体热点传播研究的学者而言,他们能够通过分析所获取的时间序列和热度数据,洞察传播动态。例如,探究某个话题在特定时间范围内热度急剧上升的具体原因。
企业能够掌握公众对产品相关议题的兴趣程度。当某公司产品相关的热门话题热度持续攀升,企业可考虑增加营销资金的投入。您是否思考过,利用Python抓取微博热搜榜信息,能为您带来哪些益处? |
|