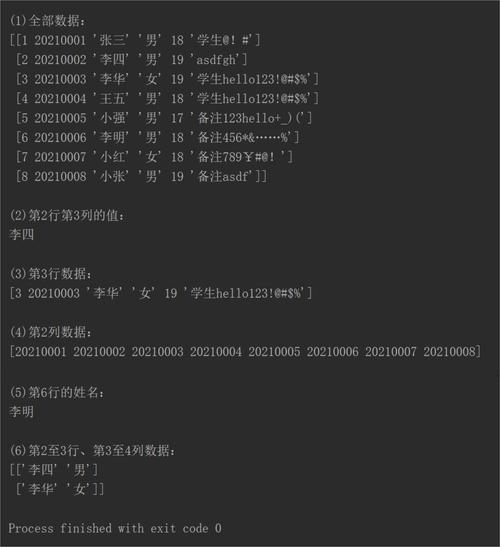
当前社交媒体高度发达,微博上每日涌现大量话题和热议内容。若能有效运用热点监测技术,对多个行业领域具有深远影响。Python编程语言在此技术实现上提供了强有力的工具。以下是相关详细说明。
数据获取途径
检测微博上的热门话题,首先需要获取相关数据。这一过程可以通过多种途径实现,例如利用微博提供的开放API接口实时抓取微博数据,或者使用事先收集好的微博数据集。以本人为例,曾经采用基于scrapy框架的爬虫技术来收集所需数据。用户可以尝试使用微博官方提供的API,具体操作包括:首先,需登录微博开放平台进行注册并设立开发者账户;其次,在所创建的应用中获取API的使用权限,这包括但不限于读取用户微博内容、搜索微博等功能;另外,还需要在命令行界面安装Python的requests库。
数据获取案例
小张,一位开发者,意图对特定时间段的娱乐微博热门话题进行深入分析。他借助微博官方提供的API接口,成功收集了众多娱乐明星的微博数据。完成账号注册和权限申请后,他利用已安装的requests库,顺利完成了数据的下载任务。这一过程说明,只要遵循正确的操作流程,无论是通过爬虫技术还是使用API,均能有效地获取到所需的微博数据,为后续的热点检测工作奠定了基础。
文本预处理操作
在获取微博数据之后,文本预处理步骤显得尤为重要。该步骤涵盖了剔除特殊符号、进行词语拆分以及淘汰无关词汇等环节。Python平台提供了众多卓越的开源文本处理工具,如NLTK和Jieba,利用这些工具可以高效地完成上述任务。该句子经过改写后为:“今日,我心情愉悦,探访了趣味盎然的场所。”
预处理效果示例
小王对体育类微博数据进行了初步处理。通过运用NLTK和Jieba工具,原本混乱的文本变得井然有序。在剔除无关词汇后,核心信息变得更加显著。此举有助于提升后续处理的效率和精确度,使得计算机能够更顺畅地解读文本,从而为精确捕捉热点话题提供了坚实的支持。
<p><pre> <code class="language-python">import pandas as pd
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
from collections import Counter
# 定义你的停用词列表
stopwords = ["的", "是", "在", "有", "和", ...] # 此处需要你提供适合你数据的停用词
# 文本预处理
def preprocess(text):
seg_list = jieba.cut(text, cut_all=False) # 分词
seg_list = [word for word in seg_list if word not in stopwords] # 去除停用词
return " ".join(seg_list)
# 加载数据
df = pd.read_csv('D:\Desktop\对应的数据文件.csv', encoding='GBK')
data = df['text'].tolist()
data = [preprocess(text) for text in data]
</code></pre></p>
文本特征提取要点
在话题检测之前,需将文本资料转换为机器学习算法所需的特征向量。Scikit-learn库在Python中具备特征提取的能力。例如,针对微博内容,该库可将文本信息转换为计算机可解析的向量格式。向量中包含词语的权重及位置等关键信息,从而便于机器学习算法进行后续处理。
<p><pre> <code class="language-python"># 特征提取
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(data)</code></pre></p>
特征提取应用场景
某数据分析团队在检测科技微博热点时,运用了Scikit-learn库进行特征提取。提取出的特征向量能够明确展示各类科技话题的独特属性。基于这些向量,团队迅速完成了后续分析,精准识别出科技领域的热点话题,例如人工智能的新应用等,凸显了特征提取在热点检测中的关键作用。
话题聚类方法
文本特征向量获取后,可通过聚类技术对微博内容进行分类,将内容相似度高的归入同一组。常用的聚类方法包括K-means和层次聚类等,这些算法在Scikit-learn库中均有对应实现。比如,可以将涉及旅游的微博内容归为一组,将讨论美食的微博归为另一组,以此便于对不同主题类别进行分析。
<p><pre> <code class="language-python"># 聚类
kmeans = KMeans(n_clusters=5, random_state=0, init='k-means++').fit(X)</code></pre></p>
聚类实例分析
在针对时尚微博的聚类分析中,采用了K-means算法。此算法对特征向量进行解析,从而精确地区分了诸如服装搭配、美妆产品评价等多样化的时尚议题。各分类中的微博内容高度相似,从而使得时尚领域的热点趋势清晰可见,便于工作人员依据聚类结果迅速把握各时尚方向的热度。
话题热度计算方式
根据聚类分析结果,可以计算出各话题的受欢迎程度。这一程度可以通过微博的转发次数、评论数、点赞数等数据进行评估。通过为这些数据赋予不同权重,并进行加权求和,可以得出各话题的热度指数。例如,若将某话题的转发次数权重设定为0.5,评论次数权重为0.3,点赞次数权重为0.2,那么在统计各自数值后,按照这些权重进行计算,即可得出该话题的热度值。
<p><pre> <code class="language-python"># 提取主题词
order_centroids = kmeans.cluster_centers_.argsort()[:, ::-1]
terms = vectorizer.get_feature_names()
# 获取每个聚类的主题词
def get_topic_words(i):
return [terms[ind] for ind in order_centroids[i, :10]]
# 打印每个聚类的主题词
for i in range(5):
print("Cluster %d:" % i, get_topic_words(i))
# 对所有聚类的主题词进行计数
topic_counter = Counter([word for i in range(5) for word in get_topic_words(i)])
# 打印出现次数最多的10个主题词
print("Top 10 hot topics:")
for word, count in topic_counter.most_common(10):
print("%s: %d" % (word, count))
# 计算热度得分
def calculate_hot_score(cluster):
# 获取该聚类的所有微博
cluster_tweets = df[kmeans.labels_ == cluster]
# 计算话题的出现频次
frequency = len(cluster_tweets)
# 计算相关微博的总评论数和总点赞数
total_comments = cluster_tweets['comments_count'].sum()
total_attitudes = cluster_tweets['attitudes_count'].sum()
# 返回一个得分,这个得分是频次、评论数和点赞数的加权平均
# 这里假设所有因素的权重都是1,你可以根据实际需要调整权重
return (frequency + total_comments + total_attitudes) / 3
# 计算每个聚类的热度得分
hot_scores = [calculate_hot_score(i) for i in range(5)]
# 打印每个聚类的热度得分
for i, score in enumerate(hot_scores):
print("Cluster %d:" % i, get_topic_words(i))
print("Hot score: %f" % score)</code></pre></p>
热度展示效果
该机构在分析娱乐微博热门话题后,借助Matplotlib和Seaborn工具制作了柱状图及词云图表。通过柱状图,可以直观地观察到不同娱乐话题的热度差异;而词云则凸显了热门话题的核心词汇。此举有助于工作人员迅速了解娱乐热点,同时也便于向公众有效传播相关信息。
<p><pre> Cluster 0: ['挑战', '光盘', '接力', '节约粮食', '行者', '活动', '参与', 'XX大学', '东北', '干饭']
Cluster 1: ['XX大学', '东北', '绿色', '生活', '行者', '节约粮食', '干饭', '日记', '光盘', '云财管']
Cluster 2: ['学校', '快递', '东北', 'XX大学', '现在', '可以', '开学', '什么', '一下', '咱们']
Cluster 3: ['东北', 'XX大学', '开学', '有没有', '一个', '春天', '什么', '真的', '可以', '大庆']
Cluster 4: ['学姐', '学长', '复试', '专硕', '会计', '资料', '东北', 'XX大学', '上岸', '考研']
Top 10 hot topics:
XX大学: 5
东北: 5
光盘: 2
节约粮食: 2
行者: 2
干饭: 2
可以: 2
开学: 2
什么: 2
挑战: 1
Cluster 0: ['挑战', '光盘', '接力', '节约粮食', '行者', '活动', '参与', 'XX大学', '东北', '干饭']
Hot score: 1483.000000
Cluster 1: ['XX大学', '东北', '绿色', '生活', '行者', '节约粮食', '干饭', '日记', '光盘', '云财管']
Hot score: 1612.666667
Cluster 2: ['学校', '快递', '东北', 'XX大学', '现在', '可以', '开学', '什么', '一下', '咱们']
Hot score: 10343.333333
Cluster 3: ['东北', 'XX大学', '开学', '有没有', '一个', '春天', '什么', '真的', '可以', '大庆']
Hot score: 48906.000000
Cluster 4: ['学姐', '学长', '复试', '专硕', '会计', '资料', '东北', 'XX大学', '上岸', '考研']
Hot score: 1007.333333</pre></p> |
|